Decouple-Then-Merge
扩散模型的不同去噪时间步之间存在梯度冲突。DeMe 提出:先解耦训练,再合并参数——将多任务学习的负迁移转化为正收益,零额外推理成本,6 个基准显著提升生成质量。
扩散模型在所有时间步共享参数。但不同时间步的去噪任务本质不同:大时间步生成低频内容(构图、结构),小时间步生成高频细节。共享参数 = 强迫一个模型同时做 N 个互相冲突的任务 = 梯度互相拉扯 = 谁也做不好。
梯度冲突:被忽视的训练瓶颈
扩散模型训练的核心矛盾——为什么共享参数既是优势又是诅咒
扩散模型的训练本质上是在做多任务学习:从 t=0 到 t=T 的每个时间步都是一个独立的去噪任务,但它们共享同一组模型参数。共享的好处显而易见——训练效率高,不同任务间可以互相借力。
但代价呢?论文通过计算不同时间步梯度之间的余弦相似度,揭示了一个被忽视的事实:
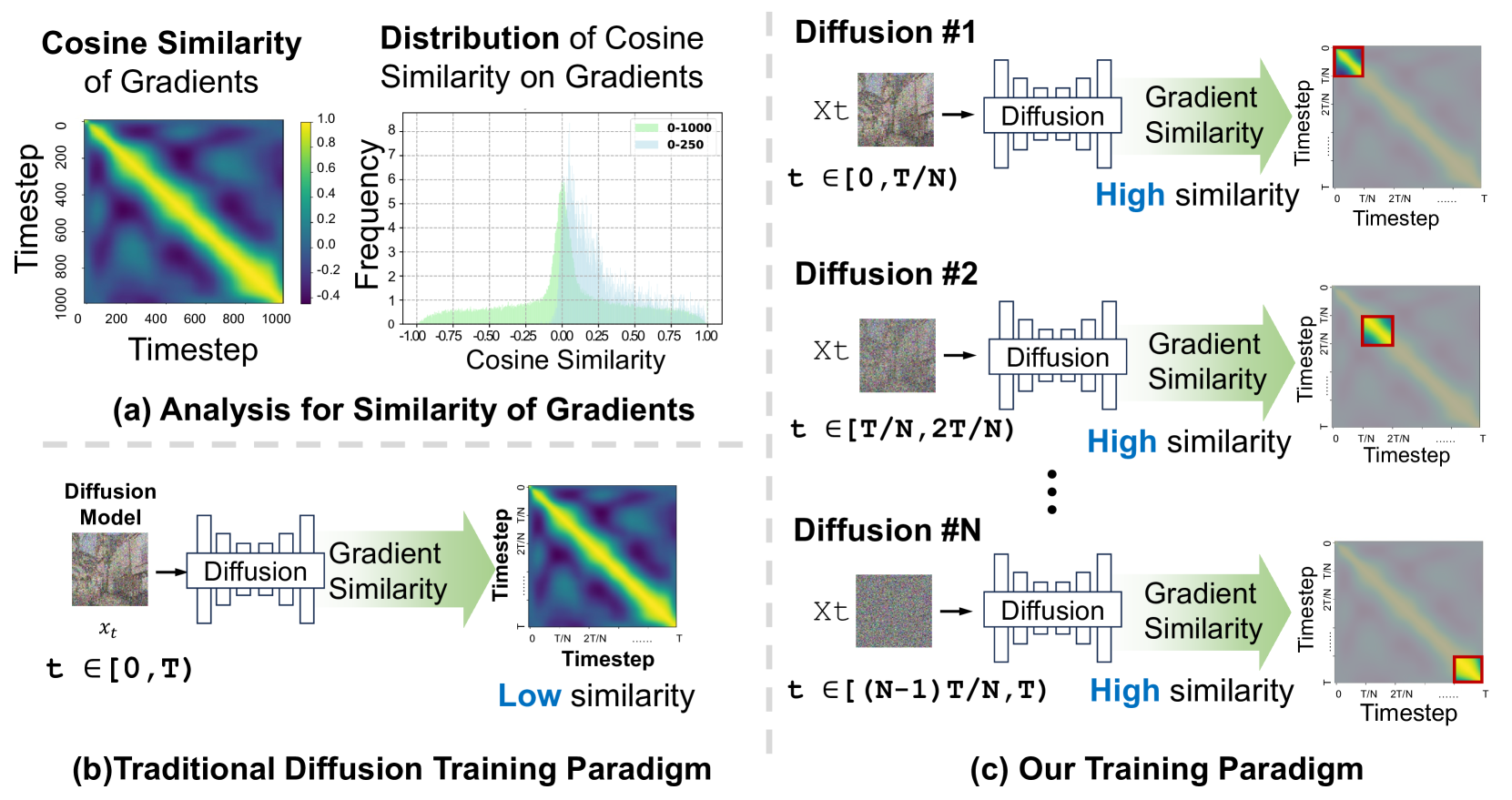
(a) 左上 · 热力图:横轴和纵轴都是时间步 0→1000。每个格子的颜色代表两个时间步梯度的余弦相似度——亮黄色=高度相似(梯度方向一致),深蓝色=相似度低甚至为负(梯度方向冲突)。注意对角线附近是亮黄色(相邻时间步方向一致),但远离对角线就变成深蓝色——说明 t=100 和 t=800 的梯度在"打架"。
(a) 右上 · 直方图:绿色=全范围 [0,1000] 的梯度相似度分布,集中在 0 附近(大部分时间步对之间几乎不相关);蓝色=缩小到 [0,250],分布右移向正值(短程内相似度更高)。
(b) 左下:传统方案——一个模型承接所有时间步,梯度相似度低(冲突严重)。
(c) 右侧:DeMe 方案——每个模型只负责一个子区间,各自内部梯度相似度高(冲突消除)。
热力图的信息量很大,值得细看。核心结论只有一个:不相邻时间步之间的梯度方向几乎不相关甚至相反。这不是训练不够的问题——
不同时间步到底在做什么?
已有研究(Fang et al.)表明,扩散模型在不同时间步承担本质不同的任务:
让一个画家同时学"画草图"和"上油彩",梯度告诉我们:这两项技能的优化方向是冲突的。传统方案——loss 重加权——只能调节各任务的"音量",但解决不了它们方向上的矛盾。
与多任务学习的对应关系
DeMe 框架:解耦训练,参数合并
核心思路——把一个多任务问题拆成 N 个单任务,训完再融合
DeMe 的框架极其优雅:从预训练模型出发,拆分时间步范围,各自微调,最后在参数空间合并回一个模型。推理时仍然是一个模型、没有任何额外开销——但生成质量显著提升。
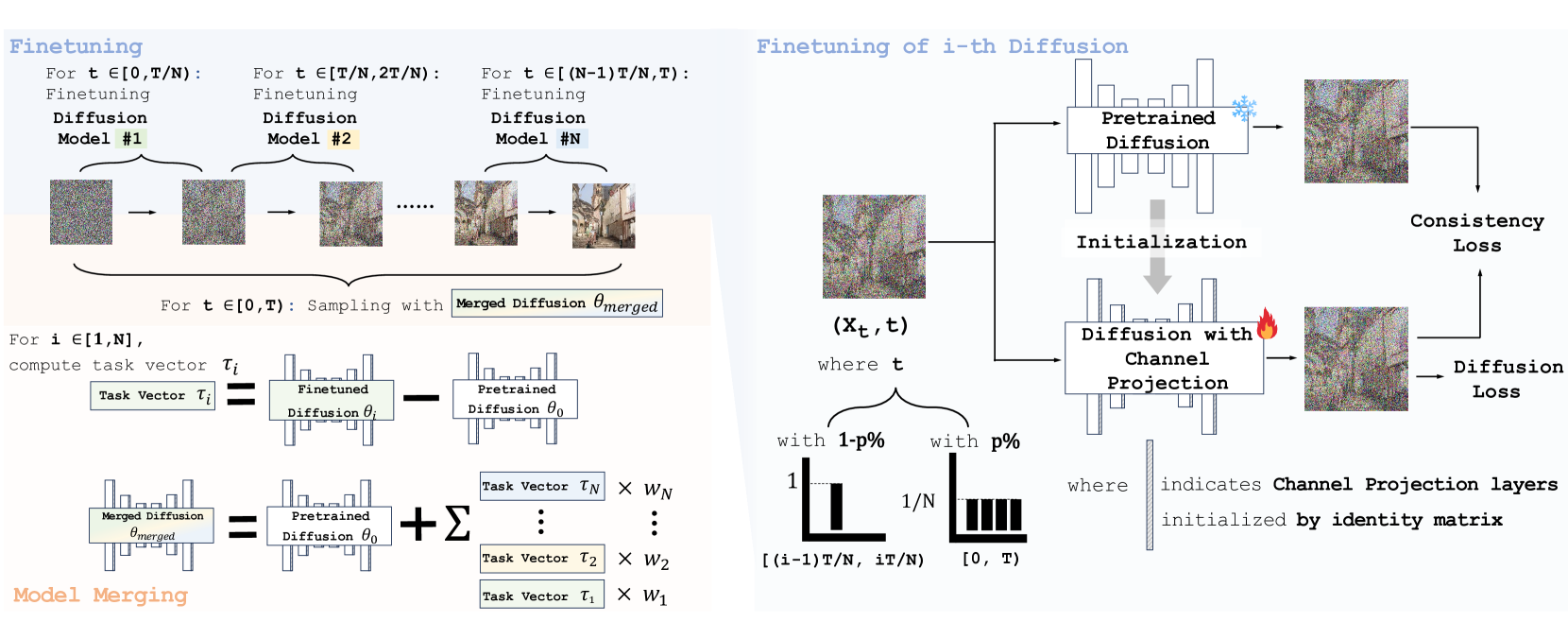
这张图分左右两半,建议先看左边再看右边。
左半 · 整体流程:上方——预训练模型被复制为 N 份,每份只在自己的时间步区间 [0,T/N)、[T/N,2T/N)、... 上微调。下方——微调完成后,计算每个模型相对于预训练模型的差异(task vector τᵢ = θᵢ − θ),加权求和后叠加回预训练模型,得到单一的 θmerged。
右半 · 单个模型怎么训:输入 (xt, t) 送入带 Channel Projection 层(初始化为单位矩阵)的扩散模型。时间步 t 的采样策略:以 (1-p)% 概率从对应子区间采样(左侧高柱),以 p% 概率从全范围 [0,T) 采样(右侧矮柱)。输出同时计算两个 loss——Diffusion Loss(去噪准确度)和 Consistency Loss(与原始模型的一致性)。
Step 1:解耦训练
将 [0, T) 等分为 N 个不重叠的时间步区间:
每个区间对应一个独立微调的模型 εθᵢ,只用该区间内的时间步计算 loss。这样,不同区间的梯度永远不会在同一模型的参数上累加——冲突被物理隔离了。
Step 2:三项训练技术
纯粹的解耦会带来新问题:每个微调模型只见过一部分时间步,可能遗忘其他时间步的知识,或过拟合到自己的子区间。论文引入三项技术来平衡"隔离冲突"与"保留共享":
Channel-wise Projection
在中间特征上加一个可学习的 C×C 投影矩阵(初始化为单位矩阵)。论文发现微调前后的激活差异主要集中在通道维度而非空间维度,这个投影层直接捕捉通道映射的变化。参数量仅占模型的 1.06%。
Consistency Loss
微调时加一项额外损失:让微调后模型的输出不要偏离原始预训练模型太远。这像一根"弹簧"——允许模型在子区间上优化,但防止它走得太远、丢失全局知识。
Probabilistic Sampling
以概率 (1-p) 从对应子区间采样时间步,以概率 p 从完整范围 [0, T) 采样。主攻自己的区间,但偶尔"回顾"其他区间的知识,防止灾难性遗忘。
三项技术的消融贡献
Step 3:参数空间合并
微调后得到 N 个模型 {θ₁, θ₂, ..., θN}。直接集成推理(ensemble)需要 N 倍存储——不实际。论文采用任务向量(Task Arithmetic)做参数合并:
θ_merged = θ + Σ wᵢ · τᵢ
每个 task vector τᵢ 编码了"第 i 个区间相对于预训练模型学到的增量知识"。加权求和后叠加回预训练模型,得到一个融合了所有区间知识的单一模型。权重 wᵢ 通过网格搜索确定。
实验结果:6 个基准的硬数据
不是边际改进——是在成熟基线上的显著跳跃
无条件图像生成(DDPM)
| 方法 | CIFAR10 FID↓ | LSUN-Church FID↓ | LSUN-Bedroom FID↓ |
|---|---|---|---|
| 预训练基线 DDPM | 4.42 | 10.69 | 6.46 |
| Min-SNR-γ | 5.77 (+1.35) | 10.82 | 6.41 |
| P2 Weighting | 5.63 (+1.21) | 10.77 | 6.53 |
| ANT-UW 最强基线 | 4.21 | 10.43 | 6.48 |
| DeMe (集成) N 个模型 | 3.79 (-0.63) | 9.57 | 5.87 |
| DeMe (合并) 1 个模型 | 3.51 (-0.91) | 7.27 (-3.42) | 5.84 (-0.62) |
FID 改进
FID 改进
FID 改进
文生图(Stable Diffusion)
| 方法 | COCO FID↓ | COCO CLIP↑ | ImageNet FID↓ | PartiPrompts CLIP↑ |
|---|---|---|---|---|
| Stable Diffusion 基线 | 13.42 | 29.88 | 27.62 | 29.78 |
| ANT-UW | 13.17 | 29.94 | 26.91 | 29.98 |
| DeMe (合并) 最优 | 13.06 | 30.11 | 27.23 | 29.98 |
在文生图任务上,DeMe 合并方案的亮点是同时提升了图像质量和文本对齐度:COCO 上 FID 降了 0.36 的同时 CLIP Score 提了 0.23——这两者通常是此消彼长的。集成方案虽然 FID 降幅更大(-0.64),但 CLIP Score 反而下降了 0.03。
定性对比:微调前 vs 后

每组对比中,左图=微调前(原始 Stable Diffusion),右图=DeMe 微调后。蓝色斜体标注了 prompt 中模型未能对齐的关键描述。
Prompt I"白马在野花田中奔跑":微调前缺失"日落"场景(as the sun sets behind it),微调后完整还原了夕阳背景和飘动的鬃毛。
Prompt II"热带海滩":微调前缺失"白色沙滩"(white sandy shores),微调后沙滩、棕榈树、清澈海水全部到位。

同样左=微调前,右=微调后。
Prompt III"海豚跃出海面":微调前缺失"日落在地平线上"(sun sets on the horizon),画面平淡;微调后呈现出金色逆光剪影,水花飞溅动感十足。
Prompt IV"雾蒙蒙的乡村早晨,一间小木屋":微调前完全忽略了"小木屋"(a small wooden cabin)这一核心元素;微调后木屋、野花、晨雾、透过雾气的阳光全部准确呈现。
消融实验
| N (分组数) | Channel Proj. | Prob. Sampling | Consist. Loss | FID↓ |
|---|---|---|---|---|
| 1 | ✗ | ✗ | ✗ | 4.40 传统训练 |
| 1 | ✓ | ✗ | ✗ | 4.45 (+0.05, 变差) |
| 8 | ✗ | ✓ | ✗ | 4.32 |
| 8 | ✗ | ✓ | ✓ | 4.27 |
| 8 | ✓ | ✓ | ✓ | 3.87 全部启用 |
- 解耦是必要条件:Channel-wise Projection 在 N=1 时无效甚至有害,但在 N=8 时贡献最大(FID -0.40)。原因:不解耦时所有时间步的通道差异混杂在一起,C×C 矩阵学不到有意义的映射。
- Probabilistic Sampling 和 Consistency Loss 各自贡献 0.08 和 0.05 的 FID 改进——它们的作用是防止过拟合到子区间和遗忘全局知识。
- 全部叠加时有协同效应:总改进 0.53,大于各项之和——三项技术相互增强。
为什么有效:Loss Landscape 的视角
从损失地形和任务向量两个视角,理解 DeMe 的底层机制
临界点逃逸
论文可视化了预训练模型在不同时间步范围上的 loss landscape(图 4)。两个关键发现:
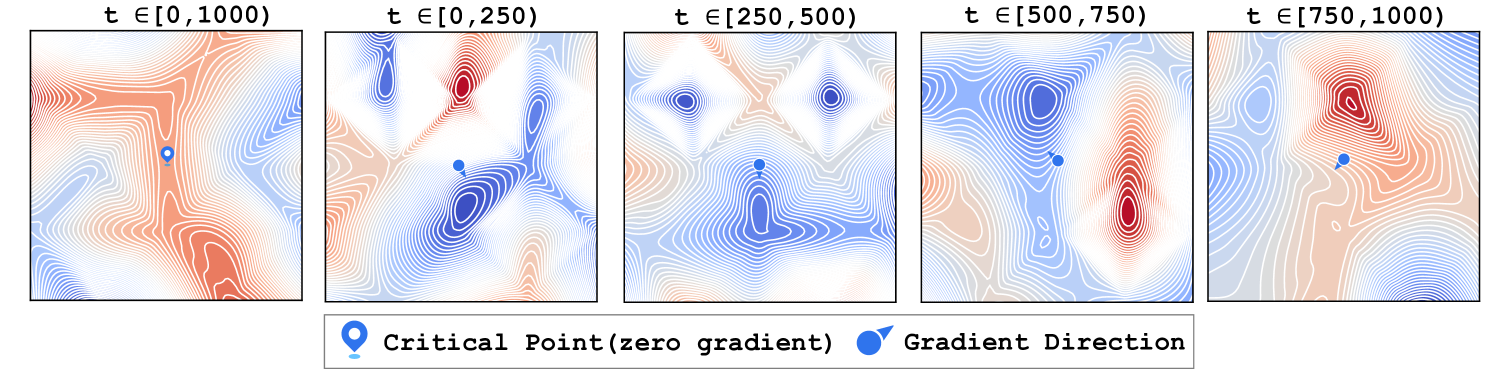
5 幅子图从左到右分别对应不同的时间步范围。每幅是一个二维 loss landscape(通过降维将高维参数空间投影到 2D)。蓝色=低 loss,红色=高 loss。等高线越密=地形越陡=梯度越大。
浅蓝色大标记 📍 = 预训练模型所在位置(临界点,梯度为零);深蓝色小标记 = 梯度方向(该点可以继续优化的方向)。
关键对比:最左侧 t∈[0,1000)(完整范围)——模型 📍 所在区域等高线极其稀疏,地形几乎平坦,看起来已经"到底了"。但看其他 4 幅子图(子区间)——同一个位置周围等高线突然变密,出现了明确的"下坡路"。全局看似到底 ≠ 局部到底——模型卡在一个各方向梯度互相抵消的折中点,解耦后每个子区间都能找到继续优化的方向。
这就是 DeMe 有效的底层原因:全局看似收敛的模型,在局部视角下远未收敛。解耦训练让模型在每个子区间上沿着各自的梯度方向独立优化,逃离折中的临界点。
Task Vector 分析
论文可视化了不同时间步范围的 task vector 幅度(图 6b):
参数空间中的最优点
论文将两个 task vector 张成的平面上的 loss 进行可视化(图 6a),发现:
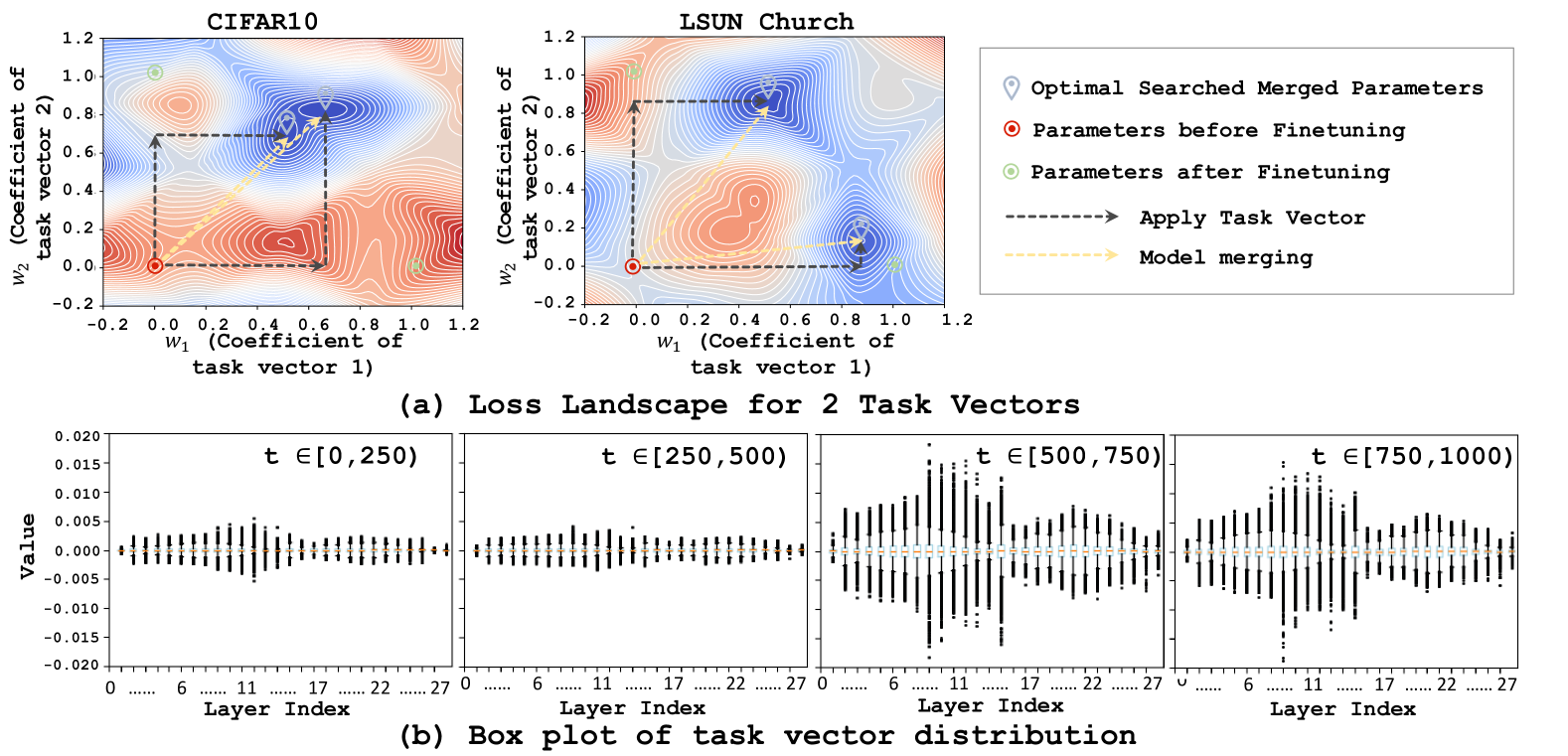
(a) 上方 · Task vector 平面上的 loss:横轴 w₁、纵轴 w₂ 分别是两个 task vector 的系数。红色圆圈 ⭕ = 预训练模型(原点附近,w₁=w₂=0);绿色圆圈 = 各微调模型(沿轴方向远离原点);紫色菱形 ◇ = 网格搜索找到的最优合并参数。蓝色=低 loss,红色=高 loss。注意最优点 ◇ 既不在预训练位置 ⭕ 也不在任何微调模型位置——它在 task vector 的加权组合方向上,loss 更低。
(b) 下方 · 箱线图:每个子图对应一个时间步子区间,横轴是模型层序号(0→27),纵轴是该层 task vector 的数值幅度。关键对比:左侧两图(t∈[0,250) 和 t∈[250,500))箱体矮且窄——微调前后参数变化小;右侧两图(t∈[500,750) 和 t∈[750,1000))箱体明显更高更宽——微调前后参数变化大,说明原始模型在大时间步上被严重欠优化。
- Loss 等高线呈盆地状——预训练模型和微调模型都不在最优点,但最优点就在它们中间
- Task vector 的加权组合可以找到比任何单个模型都更好的参数——这就是为什么合并 > 集成
- Loss 变化相对光滑,为更高级的搜索方法(如进化搜索)留出了空间
DeMe 与 Loss Reweighting 的形式等价
Channel-wise Projection 的激活分析(Figure 2)
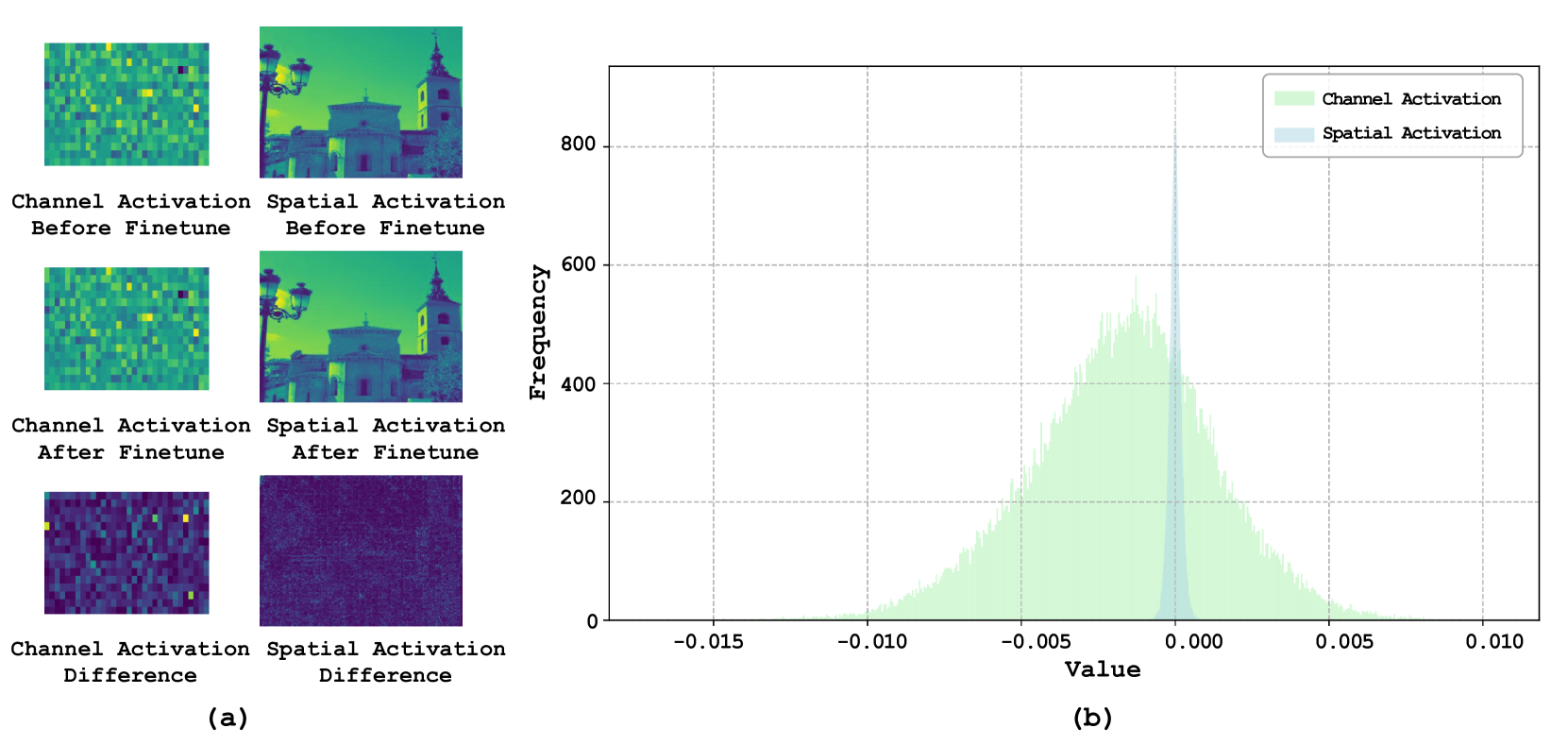 怎么读这张图
怎么读这张图(a) 左侧 · 三行可视化:每行两张热力图,左列=通道激活,右列=空间激活。第一行=微调前,第二行=微调后,第三行=差异(前后之差)。关键对比在第三行:左列(通道差异)有明显的亮黄色斑块,说明特定通道的激活值变化剧烈;右列(空间差异)几乎全是均匀的深紫色,说明空间结构几乎没变。
(b) 右侧 · 差异分布直方图:绿色=通道激活差异的分布,明显更宽(spread 大);蓝色=空间激活差异的分布,窄得多(集中在 0 附近)。
结论:微调学到的新知识主要编码在通道映射("哪些特征通道变重要了")中,而非空间映射("像素位置关系")中。这就是 Channel-wise Projection(C×C 矩阵)设计的实证依据——它精准作用在变化最大的维度上,只占模型参数的 1.06%。
设计蓝图:从论文到实践
提炼方法论层面的启示
- "训练即多任务"——扩散模型的时间步共享参数本质上是多任务学习。一旦建立这个认知,MTL 领域数十年的研究工具(梯度手术、参数隔离、任务聚类)都可以借用。
- "隔离-再融合"优于"调权重"——loss 重加权只能调"音量",不能消除方向冲突。DeMe 的路径是先物理隔离冲突,再在参数空间找到全局最优融合点。
- Task Arithmetic 的威力——参数合并的实质是在高维参数空间中做向量运算,远超简单取平均。task vector 的加权组合可以找到比任何单个模型都更好的位置。
- 微调阶段的成本换推理阶段的免费——N 倍微调成本,但推理完全零开销。对于部署场景(推理 >> 训练),这是极好的成本结构。
- 可能的泛化——论文指出,这种"任务特定训练 + 参数空间合并"的框架不限于扩散模型,可以推广到一般的多任务学习场景。
扩散模型共享参数是一种强假设,它带来了训练效率但也带来了梯度冲突。DeMe 的贡献不在于某个具体的 trick,而在于提出了一个正确的问题框架:把扩散模型训练视为多任务学习,问题就从"如何调 loss 权重"变成了"如何管理任务间的知识共享与冲突隔离"——后者有更大的解空间,也通向更好的解。